
Большой интерес пользователей к статье Учимся парсить сайты с библиотекой PHP Simple HTML DOM Parser показал, что тема парсеров очень актуальна. В продолжении темы, хочу рассказать, как можно парсить сайты используя JavaScript и всю мощь библиотеки jQuery, взамен Simple HTML DOM Parser.
Нет, мы не будем использовать для обработки js, какой-нибудь серверный интерпретатор, весь парсинг и обработка данных будет происходить на Вашей машине, в Вашем браузере. Браузером будет Google Chrome, а парсер мы реализуем в виде расширения Google Chrome Extension.
Почему Google Chrome, трудно сказать, самым верным ответом наверное будет: "А почему бы и нет?!". Не сомневаюсь, что тоже самое можно будет сделать и для Opera. Однако, эта статья не про написание расширений для браузера( хотя возможно Вы почерпнете для себя и здесь, что-то новое), а про то, как писать client-side парсеры на JavaScript.
Также хочу рассказать про преимущества, которые дает такой подход к написанию парсера.
Во первых: jQuery и JavaScript в целом обладает фантастическим набором методов для работы с DOM документа, Simple HTML DOM Parser тихо курит в сторонке. Навигация по дереву DOM браузер априори обрабатывает очень быстро, это собственно его нативный функционал.
Второе: по планете давным давно шагает WEB 2.0. Для тех кто в танке: веб второй версии подразумевает динамически меняющийся контент сайта. AJAX или просто замена определенного участка страницы через JS сводит на нет работу любого php парсера. Проиллюстрирую на примере:
<html> <body onload="document.body.innerHTML='Страница была создана динамически! Так нужный Вашему парсеру email равен leroy@xdan.ru'"> email:leroy*****.ru </body> </html>
Полагаю Вы догадываетесь, что увидит написанный на php парсер, загрузивший данную страницу, и тупо проверяющий содержание тега body.
Использование браузера в качестве парсер-машины позволяет, обмануть сайт, и выполнить подобные скрипты, получив результирующую страницу.
Итак для начала напишем расширение для Chrome типа Hello World!!!, а затем будем наращивать его функционал. Далее я буду называть наше расширение - приложением, так как расширение увеличивает функционал самого браузера, либо добавляет какие-то фичи к сайту, мы же пишем настоящее приложение, которое работает на базе браузера.
Создайте пустую папку с каким-нибудь внятным названием на латинице. Я назвал парсер xdParser, так обзовем и папку.
В ней создадим два файла main.html и manifest.json, такого содержания:
manifest.json
{
"name": "xdParser v.1.0",
"version": "1.0",
"description": "Parser sites",
"permissions": [
"http://xdan.ru/*"
],
"app": {
"launch": {
"local_path": "main.html"
}
},
"icons": { "48": "Spider-48.png", }
}
Самым интересным параметром для нашего парсера здесь будет permissions, дело в том, что по умолчанию ajax не позволяет cross-domain запросы. Прописав нужный домен в массив permissions, мы сообщаем Google Chrome'у, о том что наш ajax будет использовать кросс-доменные запросы. Если же в массив добавить "<all_urls>", то ajax-запросы будут разрешены для любого домена.
main.html
Привет Мир!!!
Чтобы новое приложение не затерялось в безликой толпе, закиньте в созданную папку набор каких-нибудь иконок, к примеру эти. Иконки должны быть png, иначе они работают не везде. Наверно глюк.
Теперь приложение надо установить, кликаем на панели браузера по иконке с гаечным ключем (Настройки и управление Google Chrome), затем Инструменты -> Расширения, ставим в самом верху галку Режим разработчика
(Настройки и управление Google Chrome), затем Инструменты -> Расширения, ставим в самом верху галку Режим разработчика
Далее кликаем Загрузить распакованное расширение... и указываем путь к вышеназванной папке. Если manifest.json валиден, то приложение установится и мы увидим его среди прочих.
Открываем новую вкладку, в ней переходим на слайд Приложения, и видим там свое.
С Hello World разобрались, теперь напишем наш первый парсер JavaScript на Google Chrome Extensions.
Изменим main.html
<html> <head> <meta http-equiv="content-type" content="text/html; charset=utf-8"/> <title>xdParser v1.1</title> <link href="css/main.css" rel="stylesheet"/> <script type="text/javascript" src="/js/jquery-1.7.2.min.js"></script> <script type="text/javascript" src="/js/main.js"></script> </head> <body> <img id="progress" src="/css/images/progress.gif"/> <input id="starter" type="button" value="Запустить парсер"/> <div id="resultbox"> </div> </body> </html>
Как видно из кода, необходимо создать две подпапки js и css. В js закинуть два файла jquery-1.7.2.min.js и main.js
main.js
(function($){
function ajaxStart(){
$('#progress').show();
}
function ajaxStop(){
$('#progress').hide();
}
function parserGo(){
ajaxStart();
var b = $.ajax('http://xdan.ru');
b.done(function (d) {
analysisSite(d);
ajaxStop();
});
b.fail(function (e, g, f) {
alert('Epic Fail');
ajaxStop();
})
}
function analysisSite(data){
var res = '';
$(data).find('a').each(function(){
res+=$(this).text()+'=>'+$(this).attr('href')+'<br/>';
})
$('#resultbox').html(res);
}
$(function(){
$('#progress').hide();
$('#starter').click(parserGo);
});
})(jQuery);
Тут все просто, на кнопку #starter вешается обработчик события onclick, функция parserGo. В ней мы загружаем главную страницу блога и при удачной загрузке вызываем функцию analysisSite. В которой происходит обработка полученных данных. Запустите парсер. Для примера я вывел все ссылки на главной сайта xdan.ru.
Теперь сделаем что-нибудь посложнее. Возьмем мой пример с парсингом фото из Яндекса при попмощи Simple HTML DOM
Изменим manifest.json
...
"permissions": [
"http://xdan.ru/*",
"http://images.yandex.ru/*"
],
...
не забывайте перезагружать Ваше приложение в расширениях Google Chrome, там же где Вы его устанавливали. Под каждым расширением, в том числе и Вашем есть ссылка Перезагрузить
Иначе изменения внесенные в manifest.json не вступят в силу.
Далее изменим parserGo
...
var url = 'http://images.yandex.ru/yandsearch?text='+encodeURIComponent('Джессика Альба')+'&rpt=image';
...
и analysisSite
$imgs = $(data).find('div.b-image img');
if( $imgs.length ){
requrs($imgs,$imgs.length-1);
}
Как видите я ввел еще одну функцию requrs:
function requrs(data,index){
res+='<img src="'+data[index].src+'"/>';
fs.loadRemoteFile('image'+index+'.jpg',data[index].src,function(){
if( index>0 )requrs(data,index-1);else $('#resultbox').html(res);
});
}
где fs это экземпляр класса fileStorage для работы с файловой системой. Для его инициализации Вам понадобится файл fileStorage.js и в самом начале main.js прописать создание экземпляра этого класса:
(function($){
var fs = new xdFileStorage();
function ajaxStart(){
...
То, как он работает, это тема отдельной статьи, отмечу лишь одни грабли в его использовании: запись следующего файла на диск должна производится только после завершения записи предыдущего. Это очень важно учитывать в асинхронных приложениях, коим и является наш парсер. Поэтому метод loadRemoteFile , одним из своих параметров принимает callback функцию, которая выполняется только по окончании записи файла на диск, и рекурсивно вызывает requrs.
По работе с файлами рекомендую почитать цикл статей по работе с файловой системой в JavaScript Работа с файлами в JavaScript, Часть 1: Основы
В результате файлы с картинками будут аккуратно сложены в папку виртуальной файловой системы Хрома, у меня это папка лежит тут: C:\Users\Leroy\AppData\Local\Google\Chrome\User Data\Default\File System, ее название может быть разным и создается самим Хромом. Повторюсь, что это лишь виртуальная файловая система, и картинок с расширением *.jpg Вы здесь не найдете. Все файлы лежат с восьмизначными числовыми именами, начиная от 00000000, без расширения. Но если открыть их какой-нибудь программой для просмотра изображений, они прекрасно откроются. А в браузере на вкладке с нашим приложением мы увидим прекрассную Джессику:
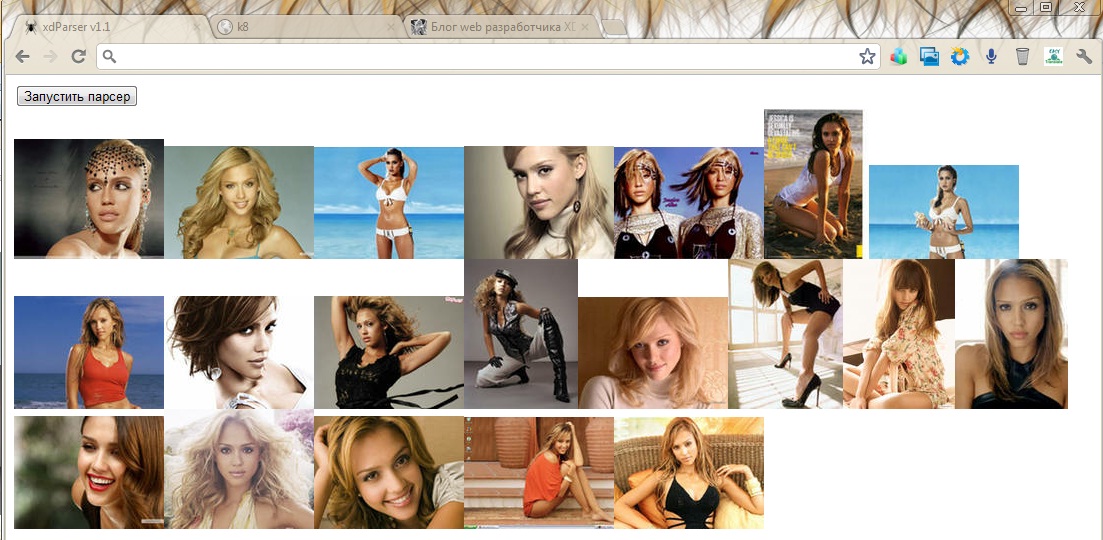
остальные примеры из парсинг фото из Яндекса при попмощи Simple HTML DOM переделайте сами, это не сложно. Мы же рассмотрим более реальный пример парсера.
Есть некая доска объявлений http://www.skelbiu.lt , к примеру нам понадобились все номера телефонов из категории Недвижимость. Для этого нам потребуется спарсить страницу http://www.skelbiu.lt/skelbimai/nekilnojamasis-turtas/ и получить список подкатегорий с их url.
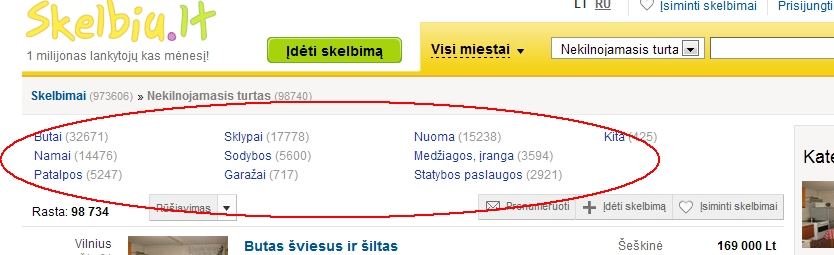
DOM Inspector Google Chrome показывает нам, что все ссылки находятся так:
function parserGo(){
$.ajax('http://www.skelbiu.lt/skelbimai/nekilnojamasis-turtas/').done(function (data) {
var s = '';
$(data).find('#categoriesDiv a').each(function(){
s+=this.innerText+'-'+'http://www.skelbiu.lt'+$(this).attr('href')+'<br/>'
})
$('#resultbox').html(s)
});
}
Отлично, у нас есть названия категорий и их адреса. Теперь необходимо выяснить сколько в каждой категории страниц с объявлениями, и перебрать их все. Для этого найдем на странице ссылку на последнюю страницу в подкатегории. Первая проблема с которой нам придется тут столкнутся, это то, что эта ссылка не имеет уникального идентификатора. Однако мы видим, что следующая за ней ссылка на Следующую страницу имеет id=nextLink, значит найти нужную нам ссылку можно так $last = $(data).find('#nextLink').parent().prev().find('a');
Также выясняется, что страницы работают без ЧПУ и у каждой подкатегории есть числовой идентификатор, он нам понадобится поэтому получим его из href найденной ссылки при помощи регулярного выражения var cat = $last.attr('href').match(/([0-9]+)\?&category_id=([0-9]+)&orderBy=[0-9]+/);
function parserGo(){
$.ajax('http://www.skelbiu.lt/skelbimai/nekilnojamasis-turtas/').done(function (data) {
var s = '';
$(data).find('#categoriesDiv a').each(function(){
s+=this.innerText+'-'+'http://www.skelbiu.lt'+$(this).attr('href')+'<br/>'
var name = this.innerText;
var url = 'http://www.skelbiu.lt'+$(this).attr('href');
$.ajax(url).done(function (data) {
$last = $(data).find('#nextLink').parent().prev().find('a'); // находим ссылку на последнюю в подкатегории страницу
var maxpage = parseInt($last.text());// сколько всего страниц
var cat = $last.attr('href').match(/([0-9]+)\?&category_id=([0-9]+)&orderBy=[0-9]+/);// выесняем id категории
requrs( cat[2],maxpage,1,url); // запускаем рекурсивную обработку страниц
});
})
$('#resultbox').html(s)
});
}
Итак у нас есть id категории cat[2] и общее количество страниц maxpage. Теперь перебираем их все с 1 до maxpage. Делать это циклом используя асинхронные запросы нецелесообразно, поэтому используем рекурсивную функцию function requrs(catid,fullCount,tik,url), где catid - это id категории, fullCount - общее количество страниц в категории, tik - текущий номер страницы, url - ЧПУ адрес подкатегории.
function requrs(catid,fullCount,tik,url){
if( tik>fullCount )return 0;// конец рекурсии
console.log('Будет спарсена страница '+tik+' категории '+catid);
$.ajax(url+tik+'&category_id='+catid+'&orderBy=1').done(function (data) {
analizeSite(data,function(){
if(tik+1<=fullCount){
requrs(catid,fullCount,tik+1,url); // рекурсивно запускаем функцию
}
},url);
});
}
Осталось распарсить полученные страницы на объявления, загрузить страницу каждого объявления и выдернуть из нее нужный нам телефон. Это сделает функция analizeSite. Каждое объявление можно найти на странице подкатегории таким образом: div.adsInfo a, а на странице с объявлением телефон можно найти регулярным выражением /<\!--googleoff\: index-->([\+0-9]+)<!--googleon: index-->/ посмотрите сами http://www.skelbiu.lt/skelbimai/butas-sviesus-ir-siltas-butas-sviesus-ir-siltas-13926351.html
function analizeSite(data,f,url){
$(data).find('div.adsInfo a').each(function(){
var dt = $.ajax({url:url+$(this).attr('href'),async:false}).responseText;
if(mch = dt.match(/<\!--googleoff\: index-->([\+0-9]+)<!--googleon: index-->/))
console.log(ticker+')Cпарсена страница '+url+$(this).attr('href')+((mch&&mch.length>1)?' найденный номер '+mch[1]:''));
})
if(f)f();// после того как будут спарсены все объявления со страницы, вызываем callback функцию, т.е. запускаем requrs с новым параметром tik
}
Результат мы увидим в консоли JavaScript, увидеть которую можно нажав ctrl+shift+j
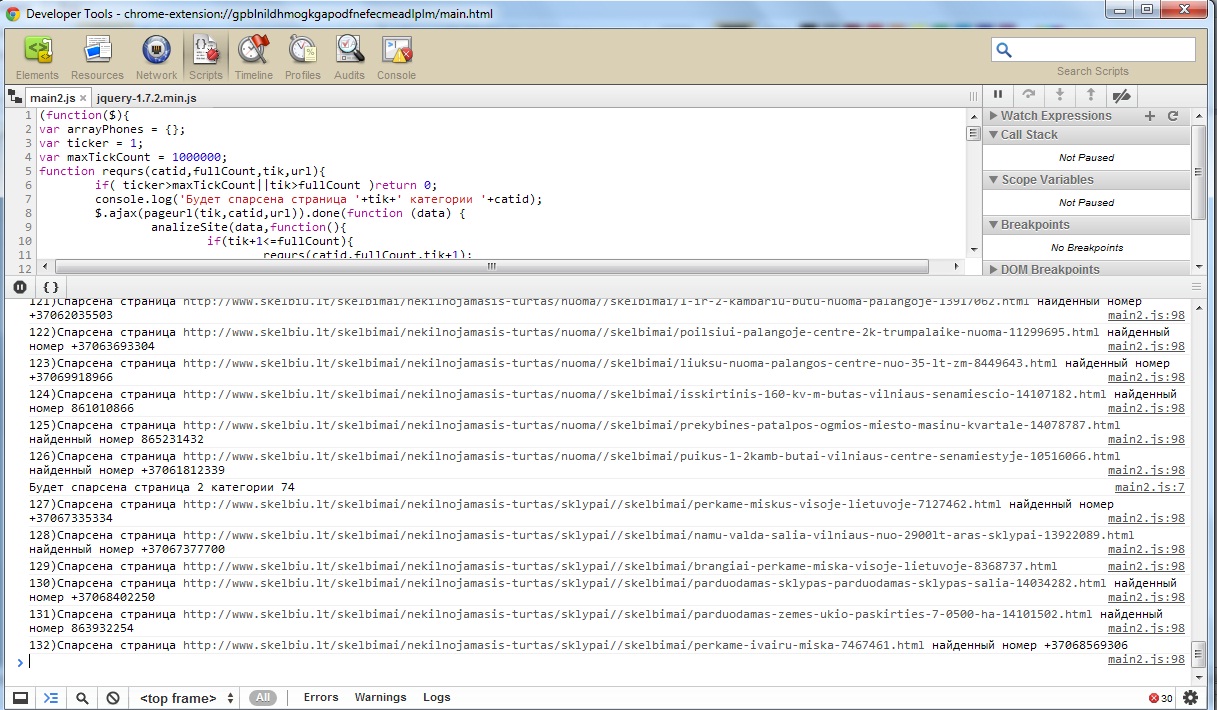
Вот и все, как всегда выкладываю все исходники с парсером xdParser v.1.1 Google Chrome Extension

Комментарии
XMLHttpRequest cannot load http://im6-tub-ru.yandex.net/i?id=183737286-42-72. Origin chrome-extension://lpobnjppnenalebacffhippolhljlmm g is not allowed by Access-Control-Allow-Origin.
как исправить?
дописал явно Url Яндекса и сайта с объявлениями..., но проблема не разрешилась (((. Что можно ещё сделать? Вопрос очень интересен...
не работает. jquery стягивает исходник, однако это не результирующая страница. т.е. она точно такая же, как если бы я зашел на целевую страницу и посмотрел её исходный код в файрфоксе или хроме. в чем проблема?
я сделал все по шагам, как здесь описано, и получил все тоже самое что можно получить с помощью PHP Simple HTML DOM Parser или обычного jQuery без заморачивания с созданием расширения для браузера?
Если есть десятки способов получить результирующую страницу (со всеми манипуляциями), почему вы не описали ни одного?
Я или что-то не понимаю, или какое-то шапито) Статья декларирует то, как получить динамически-подгружаемый контент, а по факту описывается как получить статичный контент, но через доп. грабли в виде браузера?)
Объясните плз.
Хотя идея с iframe'ом забавна) Спасибо.
Что если взять за основу этот PHP class: http://sourceforge.net/projects/snoopy/?source=recommended
Snoopy is a PHP class that simulates a web browser. It automates the task of retrieving web page content and posting forms
и когда для проверки вывожу $('#resultbox').html(data); страницу целиком. то вижу что ссылки выдачи (например запроса - блоггер) отображаются не так https://www.г- угла.com.ua/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&ved=0CC0QFjAA&url=http%3A%2F%2Fwww.blogger.com%2F&ei=RbhrUuflFcHt4gTf0IGABA&usg=AFQjCNGb2S_ihucIn-YF2o0ZlC3KCh92Aw&sig2=tTNpq2lzlkER32m60Te6RQ&bvm=bv.55123115,d.bGE
а в ввиде сразу готового линка на данный сайт www.blogger.com
Как мне получить именно тот хитрый линк ?
{ "48": "Spider-48.png", } - тут последняя запятая лишняя,
в манифест надо добавить версию манифеста - "manifest_version": 2,
а ссылки на сами сайты не выдает. Как обойти их защиту?
Почему рекурсия,а не цикл??
b.fail(function (e, g, f) {
alert('Epic Fail');
Здравствуйте подскажите откуда взялись эти e,g,f и зачем?